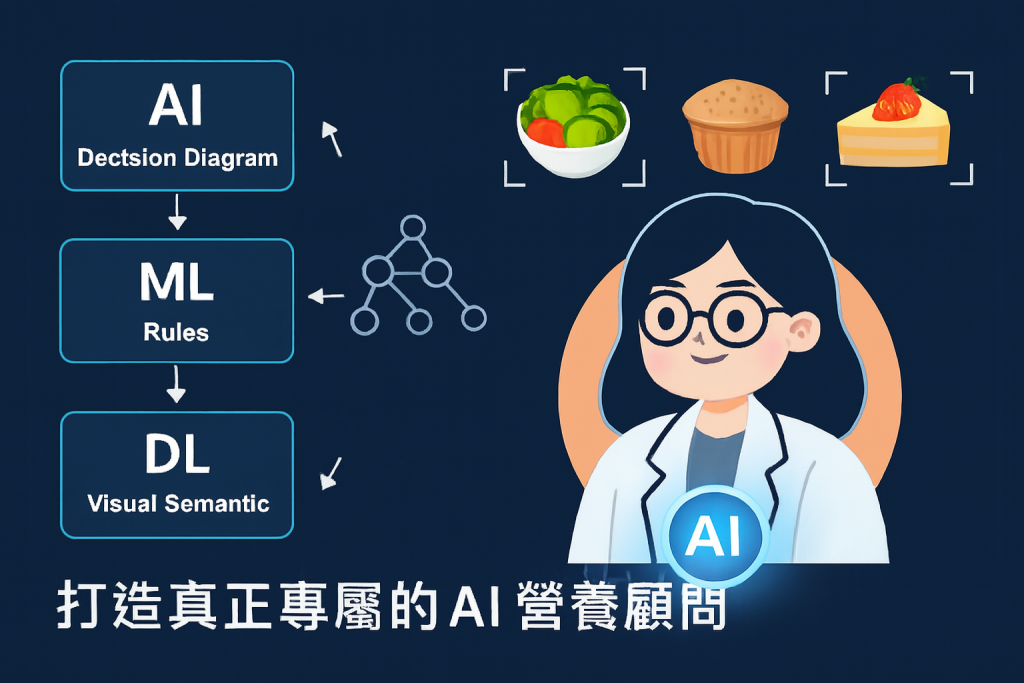
要深入探討食物圖片辨識,必須先釐清 AI、ML、DL 這三者間的遞進關係,這如同從宏觀的智慧願景,逐步聚焦到微觀的學習機制,最終觸及模仿人類感知的神經網路架構。
(由 Microsoft Copilot 協助圖片生成。)
AI 的範疇最廣,旨在模擬人類的思考、學習、決策與問題解決能力。在食物辨識的語境中,AI 代表的是整個系統的最終目標:不僅能識別食物,還能根據個人健康目標、歷史飲食習慣,甚至當前的身體狀況,給出個人化的飲食建議。例如,當系統識別出用戶攝取過多高脂食物時,AI 層次的「營養顧問」會主動提醒並推薦更健康的替代方案,這不僅僅是數據的計算,更是結合了知識推理與決策支援。
機器學習是實現 AI 的一種核心方法,它讓電腦能夠不需明確編程,透過數據自主學習規則與模式。在食物圖片辨識初期,ML 模型扮演了關鍵角色。例如:
傳統特徵工程: 早期開發者需要手動提取圖像特徵,如顏色直方圖(Color Histograms)、紋理描述符(Texture Descriptors,如 Gabor Filters)、邊緣偵測(Edge Detection,如 Canny Edge Detector)等。
分類器訓練: 這些提取出的特徵隨後被輸入到支持向量機(SVM)、決策樹(Decision Trees)、隨機森林(Random Forests)等傳統 ML 分類器中,以區分不同的食物類別,例如判斷圖像中是否為「高蛋白食材」或「蔬菜」。其核心邏輯是從大量帶標籤的數據中學習映射函數 f(x) = y,其中 x 是圖像特徵,y 是食物類別。
深度學習是機器學習的一個子集,其核心在於使用多層人工神經網路(Artificial Neural Networks, ANNs)來處理數據。DL 的最大突破在於它能夠自動從原始數據中學習更抽象、更複雜的特徵,擺脫了繁重的手動特徵工程。這尤其適用於圖像、語音這類高維度數據。
卷積神經網路 (CNNs): CNN 是圖像辨識領域的基石。其卷積層(Convolutional Layers)能自動學習圖像的局部特徵(如邊緣、角點),而池化層(Pooling Layers)則能降低維度並增加模型的平移不變性。透過多層堆疊,CNN 能夠逐步捕捉從低階到高階的語意資訊,例如從像素塊識別出「一片葉子」,進而識別出「一份沙拉」。常見架構如 ResNet、Inception、VGG 等在食物圖像分類上表現卓越。
物體偵測模型: 對於包含多種食物的餐盤,我們需要精確定位並識別每一種食物。You Only Look Once (YOLO)、Faster R-CNN、SSD 等物體偵測模型利用區域建議網路(Region Proposal Networks)和單階段/雙階段偵測策略,能同時完成食物的邊界框預測(Bounding Box Prediction)和分類。
語意分割 (Semantic Segmentation): 進一步的挑戰是精確計算食物份量。語意分割模型(如 U-Net、DeepLab)能將圖像中的每個像素點歸類到特定的食物類別,從而精確劃分出每種食物的區域,為基於體積或面積的份量估計提供基礎數據。
多模態融合 (Multi-modal Fusion) 與 Transformer: 近年來,像 Transformer 這樣的自注意力(Self-Attention)機制模型,在處理序列數據(如文字)上取得了巨大成功。結合 Vision Transformer (ViT) 或更先進的 MLLMs(如 Gemini 1.5 Pro),現在可以實現圖像與文字的深度融合理解。這意味著模型不僅能「看到」圖片中的食物,還能「讀懂」用戶提供的文字描述(例如「這是一份低脂餐點」),並生成連貫、符合語境的營養建議。這使得 AI 營養顧問能進行更精細的語意理解與生成,例如:根據圖像和用戶提問,生成一份詳細的飲食日記摘要,或推薦符合特定飲食習慣的食譜。
現代健康管理早就進入 AI 時代,但「AI」、「機器學習(ML)」、「深度學習(DL)」常讓人看得霧煞煞。簡單的說,大概就是這個樣子:
| 類型 | 定義 | 技術例子 | 假想場景 |
|---|---|---|---|
| AI | 機器能執行類似人腦的任務 | 視覺辨識、語音助理 | 讓AI決定該不該喝第二杯珍奶 |
| ML | 機器依據資料自我學習優化 | 決策樹、SVM、KNN | Machine 學會大腸包小腸VS熱狗堡 |
| DL | 使用多層神經網路實現自動特徵提取 | CNN、RNN、U-Net | 食物照片一拍自動算熱量 |

